OK, so I'm back on the blog after a 6 year break with a nice, hopefully useful article on how to overcome certain Power BI limitations when using a folder as a data source.
TL;DR --> python script is here: Github repo
 This endeavour started with the need of presenting a data trend in a line chart and all the relevant data at hand was split across hundreds .csv files, each file containing a daily summary of that data but no date information enclosed in the file.
This endeavour started with the need of presenting a data trend in a line chart and all the relevant data at hand was split across hundreds .csv files, each file containing a daily summary of that data but no date information enclosed in the file.
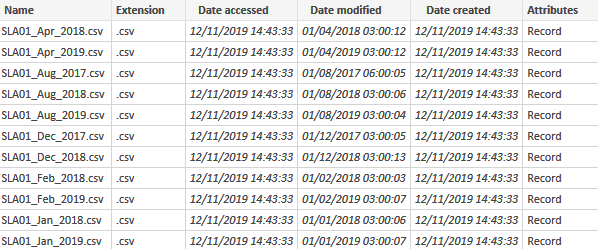
So the meta data info is all we had at hand:
 At first I tried adding all the relevant .csv files to a folder as a data source and used Power BI to get data from that folder.As it turns out Power BI can't aggregate file meta data alongside the enclosed combined data from each file.
At first I tried adding all the relevant .csv files to a folder as a data source and used Power BI to get data from that folder.As it turns out Power BI can't aggregate file meta data alongside the enclosed combined data from each file.
Or you could probably add a custom column to do that but i haven't managed to figure that one out after searching the community forums.

When combining the data you just get to play around with the file contents:
 So at this point I thought why not write a Python script that would fix this issue for me.I basically thought of parsing all the data in the .csv files and adding them as key:value pairs in a dictionary object that would be exported in a json file(which Power BI handles very well as a data source).
So at this point I thought why not write a Python script that would fix this issue for me.I basically thought of parsing all the data in the .csv files and adding them as key:value pairs in a dictionary object that would be exported in a json file(which Power BI handles very well as a data source).
The key can be the creation date or modified date of each of the .csv files and the value can be the actual data which we want to present in our time-series chart.
For this to happen we would need to use the OS, csv, datetime and json modules, a function that will read the directory and get the dates and for each date it goes through each file and grabs the contents in a respective list to that date.The script can be obtained from my Github repo.
After I've processed all the files I got a nice json file with the data structured like this:


After loading it as a data source in PowerBI with Get Data - > Json, you get something like this:
You can then convert it to a table and extract the values which are going to be separated by a delimiter.Through Power BI magic you can split them into columns and re-combine them , just in case the date format is dd/mm/yy in the file and your system is mm/dd/yy or the other way around.If you don't recombine them you will get a nasty error when trying to convert from text to date to get the time series date hierarchy.Screenshots of the subsequent transformations below:





An important thing to note is that the list positions in Python starts at 0 which caused my dates to be misaligned to the data by one day.I managed to find this out by comparing some of the report values to their previous day in the tool that generated the csv's.The fix was easy in Power BI by adding a custom column which would offset the NewDate column by -1 day:

TL;DR --> python script is here: Github repo

So the meta data info is all we had at hand:
 At first I tried adding all the relevant .csv files to a folder as a data source and used Power BI to get data from that folder.As it turns out Power BI can't aggregate file meta data alongside the enclosed combined data from each file.
At first I tried adding all the relevant .csv files to a folder as a data source and used Power BI to get data from that folder.As it turns out Power BI can't aggregate file meta data alongside the enclosed combined data from each file.Or you could probably add a custom column to do that but i haven't managed to figure that one out after searching the community forums.

When combining the data you just get to play around with the file contents:

The key can be the creation date or modified date of each of the .csv files and the value can be the actual data which we want to present in our time-series chart.
For this to happen we would need to use the OS, csv, datetime and json modules, a function that will read the directory and get the dates and for each date it goes through each file and grabs the contents in a respective list to that date.The script can be obtained from my Github repo.
After I've processed all the files I got a nice json file with the data structured like this:
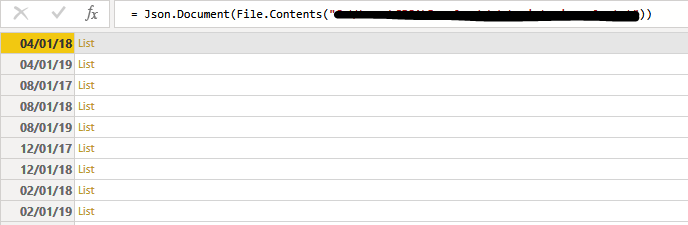
After loading it as a data source in PowerBI with Get Data - > Json, you get something like this:
You can then convert it to a table and extract the values which are going to be separated by a delimiter.Through Power BI magic you can split them into columns and re-combine them , just in case the date format is dd/mm/yy in the file and your system is mm/dd/yy or the other way around.If you don't recombine them you will get a nasty error when trying to convert from text to date to get the time series date hierarchy.Screenshots of the subsequent transformations below:





An important thing to note is that the list positions in Python starts at 0 which caused my dates to be misaligned to the data by one day.I managed to find this out by comparing some of the report values to their previous day in the tool that generated the csv's.The fix was easy in Power BI by adding a custom column which would offset the NewDate column by -1 day:

No comments:
Post a Comment